Home >> Blog >> ensemble learning 集成學習算法簡介
ensemble learning 集成學習算法簡介
集成學習是機器學習的一種通用元方法,它通過組合來自多個模型的預測來尋求更好的預測性能。
儘管您可以為預測建模問題開發看似無限數量的集成,但有三種方法在集成學習領域占主導地位。如此之多,以至於不是算法本身,而是每個研究領域都產生了許多更專業的方法。
集成學習方法的三大類是bagging、stacking和boosting,對每種方法都有詳細的了解並在您的預測建模項目中考慮它們是很重要的。
但是,在此之前,您需要對這些方法以及每種方法背後的關鍵思想進行溫和的介紹,然後再對數學和程式碼進行分層。
在本教學中,您將發現機器學習的三種標準集成學習技術。
完成本教學後,您將了解:
- Bagging 涉及在同一數據集的不同樣本上擬合許多決策樹並對預測進行平均。
- 堆疊涉及在相同數據上擬合許多不同的模型類型,並使用另一個模型來學習如何最好地組合預測。
- 提升涉及順序添加集成成員,以糾正先前模型所做的預測並輸出預測的加權平均值。
讓我們開始吧。

教學概述
本教學分為四個部分:
- 標準集成學習策略
- Bagging 集成學習
- 堆疊集成學習
- 促進集成學習
標準集成學習策略
集成學習是指結合兩個或多個模型的預測的算法。
儘管實現這一目標的方法幾乎是無限的,但在實踐中最常討論和使用的集成學習技術可能有三類。它們的受歡迎程度在很大程度上是由於它們易於實施並且在廣泛的預測建模問題上取得了成功。
在過去的幾年中,已經開發了豐富的基於集成的分類器集合。然而,其中許多是選擇的少數成熟算法的一些變體,這些算法的能力也已經過廣泛測試和廣泛報導。
鑑於它們的廣泛使用,我們可以將它們稱為“標準”集成學習策略;他們是:
- 裝袋。
- 堆疊。
- 助推。
有一種算法可以描述每種方法,儘管更重要的是,每種方法的成功催生了無數的擴展和相關技術。因此,將每一個都描述為集成學習的一類技術或標準方法更為有用。
與其深入研究每種方法的細節,不如逐步了解、總結和對比每種方法。同樣重要的是要記住,儘管對這些方法的討論和使用無處不在,但這三種方法本身並不能定義集成學習的範圍。
接下來,讓我們仔細看看bagging。
Bagging 集成學習
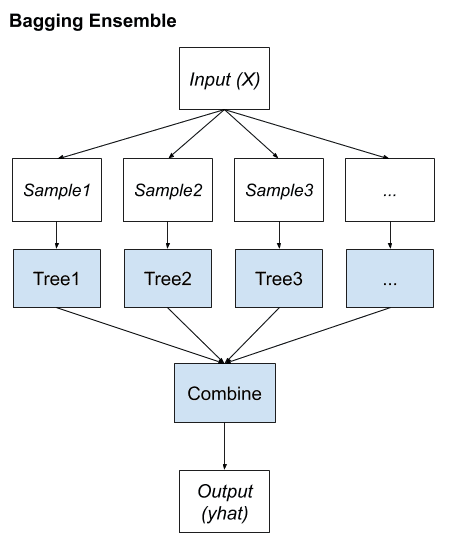
Bootstrap 聚合,或簡稱 bagging,是一種集成學習方法,它通過改變訓練數據來尋找不同的集成成員組。
"Bagging 這個名字來源於 Bootstrap AGgregating 的縮寫。顧名思義,Bagging 的兩個關鍵成分是引導和聚合。"
這通常涉及使用單個機器學習算法,幾乎總是未經修剪的決策樹,並在同一訓練數據集的不同樣本上訓練每個模型。然後使用簡單的統計數據(例如投票或平均)組合集成成員所做的預測。
"集成中的多樣性是由訓練每個分類器的自舉副本內的變化來確保的,以及通過使用相對較弱的分類器,其決策邊界相對於訓練數據中相對較小的擾動可測量地變化。"
該方法的關鍵是準備數據集的每個樣本以訓練集合成員的方式。每個模型都有自己獨特的數據集樣本。
示例(行)是從數據集中隨機抽取的,儘管有替換。
"Bagging 採用 bootstrap 分佈來生成不同的基學習器。換句話說,它應用自舉抽樣來獲得用於訓練基礎學習器的數據子集。"
替換意味著如果選擇了一行,則將其返回到訓練數據集中,以便在同一訓練數據集中進行潛在的重新選擇。這意味著對於給定的訓練數據集,一行數據可能會被選擇零次、一次或多次。
這稱為引導樣本。它是一種在具有小數據集的統計中經常使用的技術,用於估計數據樣本的統計值。通過準備多個不同的引導樣本並估計統計量併計算估計的平均值,可以實現對所需數量的更好的總體估計,而不是直接從數據集中進行估計。
以相同的方式,可以準備多個不同的訓練數據集,用於估計預測模型並進行預測。對模型中的預測進行平均通常會比直接擬合訓練數據集的單個模型產生更好的預測。
我們可以總結 bagging 的關鍵要素如下:
- 訓練數據集的引導樣本。
- 未修剪的決策樹適合每個樣本。
- 簡單的投票或平均預測。
總之,bagging 的貢獻在於用於適應每個集成成員的訓練數據的變化,這反過來又導致了熟練但不同的模型。
這是一種通用方法,易於擴展。例如,可以對訓練數據集進行更多更改,可以替換適合訓練數據的算法,以及可以修改用於組合預測的機制。
許多流行的集成算法都基於這種方法,包括:
- 袋裝決策樹(規範裝袋)
- 隨機森林
- 額外的樹
接下來,讓我們仔細看看堆疊。
堆疊集成學習
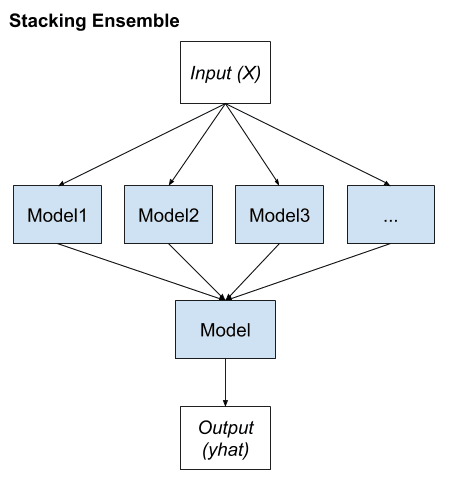
堆疊泛化,或簡稱堆疊,是一種集成方法,它通過改變適合訓練數據的模型類型並使用模型來組合預測來尋找不同的成員組。
"Stacking 是一個通用過程,在該過程中,學習者被訓練以組合各個學習者。在這裡,單個學習器被稱為第一級學習器,而組合器被稱為第二級學習器或元學習器。"
Stacking 有自己的命名法,其中集成成員稱為 0 級模型,用於組合預測的模型稱為 1 級模型。
儘管可以使用更多層的模型,但模型的兩級層次結構是最常見的方法。例如,我們可能有 3 個或 5 個 1 級模型和一個 2 級模型,它結合了 1 級模型的預測來進行預測,而不是單個 1 級模型。
堆疊可能是最流行的元學習技術。通過使用元學習器,該方法試圖推斷出哪些分類器是可靠的,哪些不可靠。
任何機器學習模型都可用於聚合預測,儘管通常使用線性模型,例如用於回歸的線性回歸和用於二元分類的邏輯回歸。這鼓勵模型的複雜性駐留在較低級別的集成成員模型和簡單模型中,以學習如何利用所做的各種預測。
"使用可訓練的組合器,可以確定哪些分類器可能在特徵空間的哪個部分成功,並相應地組合它們。"
我們可以將堆疊的關鍵要素總結如下:
- 不變的訓練數據集。
- 每個集成成員的不同機器學習算法。
- 機器學習模型,用於學習如何最好地結合預測。
多樣性來自用作集成成員的不同機器學習模型。
因此,最好使用一套以非常不同的方式學習或構建的模型,確保它們做出不同的假設,進而減少相關的預測誤差。
許多流行的集成算法都基於這種方法,包括:
- 堆疊模型(規範堆疊)
- 混合
- 超級合奏
接下來,讓我們仔細看看boosting。
促進集成學習
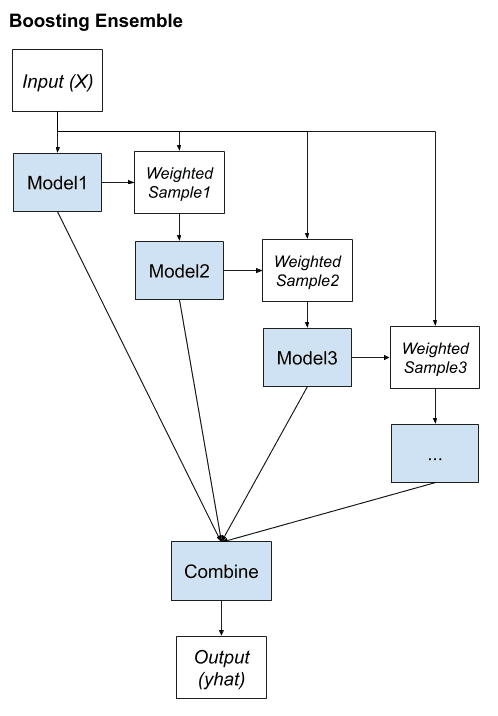
Boosting是一種集成方法,旨在更改訓練數據以將注意力集中在訓練數據集上的先前擬合模型出錯的示例上。
在 boosting 中,每個後續分類器的訓練數據集越來越關注由先前生成的分類器錯誤分類的實例。
提升集成的關鍵屬性是糾正預測錯誤的想法。這些模型被依次擬合併添加到集成中,這樣第二個模型嘗試糾正第一個模型的預測,第三個模型糾正第二個模型,依此類推。
這通常涉及使用非常簡單的決策樹,這些決策樹只做出一個或幾個決策,在提升中稱為弱學習器。弱學習者的預測使用簡單的投票或平均來組合,儘管貢獻與他們的表現或能力成正比。目標是從許多專門構建的“弱學習者”中發展出所謂的“強學習者” 。
一種用於生成強分類器的迭代方法,一種能夠從一組弱分類器中實現任意低訓練誤差的方法,每個弱分類器幾乎都比隨機猜測做得更好。
— 第 13 頁,集成機器學習,2012 年。
通常,訓練數據集保持不變,而是根據先前添加的集成成員是否正確或錯誤地預測特定示例(數據行)來修改學習算法以或多或少地關注特定示例(數據行)。例如,可以對數據行進行加權以指示學習算法在學習模型時必須給予的關注量。我們可以將 boosting 的關鍵要素總結如下:
我們可以將 boosting 的關鍵要素總結如下:
- 將訓練數據偏向那些難以預測的示例。
- 迭代地添加集成成員以糾正先前模型的預測。
- 使用模型的加權平均值組合預測。
將許多弱學習器組合成強學習器的想法最初是在理論上提出的,並且提出了許多算法,但收效甚微。直到自適應提升(AdaBoost)算法被開發出來,提升才被證明是一種有效的集成方法。
術語提升是指能夠將弱學習器轉換為強學習器的一系列算法。
自 AdaBoost 以來,已經開發了許多提升方法,其中一些方法,如隨機梯度提升,可能是對錶格(結構化)數據進行分類和回歸的最有效技術之一。
總而言之,許多流行的集成算法都基於這種方法,包括:
- AdaBoost(規範提升)
- 梯度提昇機
- 隨機梯度提升(XGBoost 和類似)
這完成了我們對標準集成學習技術的了解。
延伸閱讀
如果您想深入了解,本節將提供有關該主題的更多資源。
概括
在本教學中,您發現了機器學習的三種標準集成學習技術。
具體來說,您了解到:
- Bagging 涉及在同一數據集的不同樣本上擬合許多決策樹並對預測進行平均。
- 堆疊涉及在相同數據上擬合許多不同的模型類型,並使用另一個模型來學習如何最好地組合預測。
- 提升涉及順序添加集成成員,以糾正先前模型所做的預測並輸出預測的加權平均值。