Home >> Blog >> alexnet:挑戰 CNN 的架構?
alexnet:挑戰 CNN 的架構?
幾年前,我們仍然使用由數万張圖像組成的小型資料集,如 CIFAR 和 NORB。這些資料集足以讓機器學習模型學習基本的識別任務。然而,現實生活從來都不是簡單的,並且比這些小資料集中捕獲的變量要多得多。最近出現的像 ImageNet 這樣的大型資料集,由數十萬到數百萬張標記圖像組成,推動了對功能強大的深度學習模型的需求。然後是AlexNet。
問題。卷積神經網絡 (CNN) 一直是對象識別的首選模型——它們是易於控制甚至更易於訓練的強大模型。在用於數百萬張圖像時,它們不會出現任何驚人規模的過度擬合。它們的性能幾乎與相同大小的標準前饋神經網絡相同。唯一的問題:它們很難應用於高分辨率圖像。在 ImageNet 規模上,需要一項針對 GPU 進行優化的創新,並在提高性能的同時減少訓練時間。
資料集。ImageNet:由超過 1500 萬張高分辨率圖像組成的資料集,標記有 22000 個類別。關鍵:網絡抓取圖像和眾包人工標籤。ImageNet 甚至有自己的比賽:ImageNet 大規模視覺識別挑戰賽 (ILSVRC)。本次比賽使用 ImageNet 的圖像子集,並挑戰研究人員實現最低的 top-1 和 top-5 錯誤率(top-5 錯誤率將是正確標籤不是模型的五個最有可能標籤之一的圖像的百分比)。在這場比賽中,資料不是問題;大約有 120 萬張訓練圖像、5 萬張驗證圖像和 15 萬張測試圖像。作者通過裁剪每張圖像的中心 256x256 補丁,為他們的圖像強制執行 256x256 像素的固定分辨率。
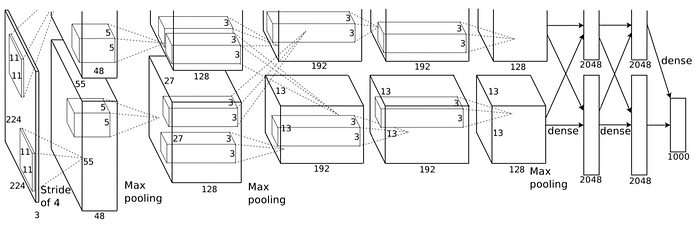
亞歷克斯網。該架構由八層組成:五個卷積層和三個全連接層。但這並不是 AlexNet 的特別之處。這些是卷積神經網絡新方法所使用的一些特徵:
- ReLU 非線性。AlexNet 使用 Rectified Linear Units (ReLU) 代替當時標準的 tanh 函數。ReLU的優勢在於訓練時間;使用 ReLU 的 CNN 能夠在 CIFAR-10 資料集上達到 25% 的誤差,比使用 tanh 的 CNN 快六倍。
- 多個 GPU。過去,GPU 仍然使用 3 GB 的內存(現在這些內存是新秀數字)。這尤其糟糕,因為訓練集有 120 萬張圖像。AlexNet 允許通過將模型的一半神經元放在一個 GPU 上,另一半放在另一個 GPU 上來進行多 GPU 訓練。這不僅意味著可以訓練更大的模型,而且還減少了訓練時間。
- 重疊池化。CNN 傳統上“匯集”相鄰神經元組的輸出,沒有重疊。然而,什麼時候作者介紹了重疊,他們發現誤差減少了約 0.5%,並發現具有重疊池的模型通常更難過擬合。
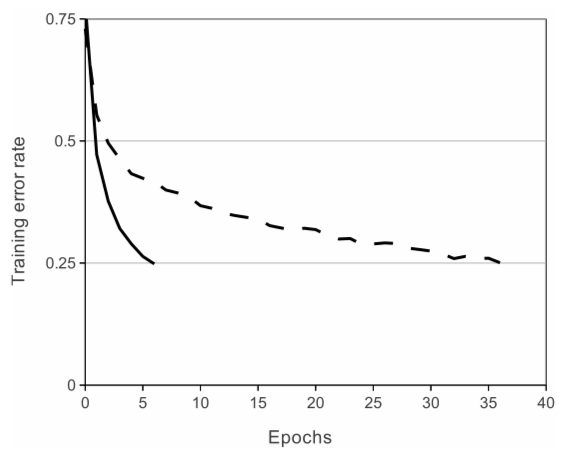
過擬合問題。AlexNet 有 6000 萬個參數,這是過擬合方面的一個主要問題。採用兩種方法來減少過擬合:
- 資料增強。作者使用標籤保留轉換來使他們的資料更加多樣化。具體來說,他們生成了圖像平移和水平反射,將訓練集增加了 2048 倍。他們還對 RGB 像素值進行了主成分分析 (PCA),以改變 RGB 通道的強度,從而減少了 top-1 錯誤率超過 1%。
- 退出。該技術包括以預定概率(例如 50%)“關閉”神經元。這意味著每次迭代都使用模型參數的不同樣本,這迫使每個神經元具有更強大的特徵,可以與其他隨機神經元一起使用。然而,dropout 也增加了模型收斂所需的訓練時間。
結果。在 2010 年版的 ImageNet 比賽中,最佳模型達到了 47.1% 的 top-1 錯誤和 28.2% 的 top-5 錯誤。AlexNet 以 37.5% 的 top-1 錯誤和 17.0% 的 top-5 錯誤大大超過了這一點。AlexNet 能夠識別偏離中心的物體,並且每個圖像的前五個類別中的大多數都是合理的。AlexNet 以 15.3% 的 top-5 錯誤率贏得了 2012 ImageNet 比賽,而第二名的 top-5 錯誤率為 26.2%。

現在怎麼辦?AlexNet 是一個非常強大的模型,能夠在極具挑戰性的資料集上實現高精度。但是,刪除任何卷積層都會大大降低 AlexNet 的性能。AlexNet 是任何對象檢測任務的領先架構,並且可能在人工智能問題的計算機視覺領域有巨大的應用。未來,AlexNet 可能會比 CNN 更多地用於圖像任務。
作為讓深度學習得到更廣泛應用的里程碑,AlexNet 也被認為將深度學習帶入了自然語言處理和醫學圖像分析等相鄰領域。