Home >> Blog >> 遞歸神經網路 RNN-Recurrent neural network 簡介
遞歸神經網路 RNN-Recurrent neural network 簡介
RNN 是一種功能強大且穩健的神經網絡,屬於最有前途的算法,因為它是唯一具有內部存儲器的算法。
與許多其他深度學習算法一樣,循環神經網絡相對較舊。它們最初是在 1980 年代創建的,但直到最近幾年我們才看到了它們的真正潛力。計算能力的提高以及我們現在必須處理的大量數據,以及 1990 年代長短期記憶 (LSTM) 的發明,確實將 RNN 帶到了前台。
由於它們的內部記憶,RNN 可以記住有關他們收到的輸入的重要訊息,這使他們能夠非常精確地預測接下來會發生什麼。這就是為什麼它們是時序數據、語音、文案、財務數據、聲音、影片、SEO優化、天氣等序列數據的首選算法。與其他算法相比,循環神經網絡可以對序列及其上下文形成更深入的理解。
但是什麼時候需要使用 RNN?
“只要有一系列數據並且連接數據的時間動態比每個單獨幀的空間內容更重要。” ——萊克斯·弗里德曼(麻省理工學院)
由於在 Siri 和Google翻譯背後的軟件中使用了 RNN,因此遞歸神經網絡在日常生活中出現了很多。
循環神經網絡如何工作
要正確理解 RNN,您需要具備“正常”前饋神經網絡和序列數據的工作知識。
順序數據基本上只是相關事物相互跟隨的有序數據。例如財務數據或 DNA 序列。最流行的序列數據類型可能是時間序列數據,它只是按時間順序列出的一系列數據點。
RNN 與前饋神經網絡
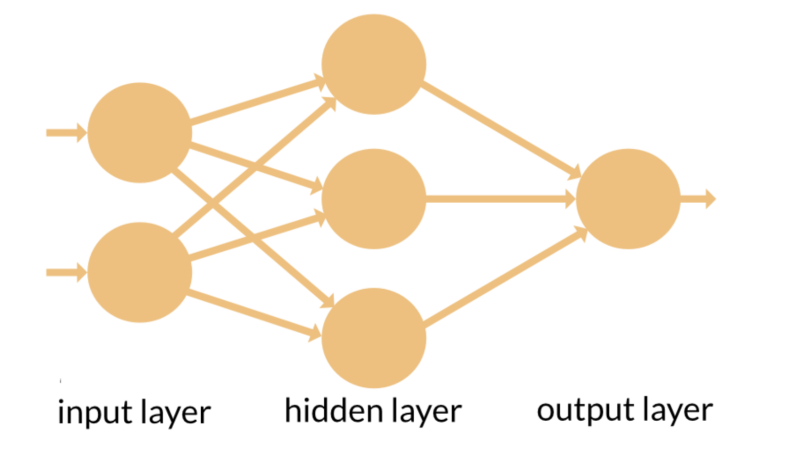
RNN 和前饋神經網絡的名稱來源於它們傳遞訊息的方式。
在前饋神經網絡中,訊息僅沿一個方向移動——從輸入層,通過隱藏層,到輸出層。訊息直接通過網絡移動,並且不會兩次觸及節點。
前饋神經網絡對它們接收的輸入沒有記憶,並且不善於預測接下來會發生什麼。因為前饋網絡只考慮當前輸入,它沒有時間順序的概念。除了訓練之外,它根本不記得過去發生的任何事情。
在 RNN 中,訊息通過一個循環循環。當它做出決定時,它會考慮當前的輸入以及它從之前收到的輸入中學到的東西。
下面的兩張圖片說明了 RNN 和前饋神經網絡之間訊息流的差異。
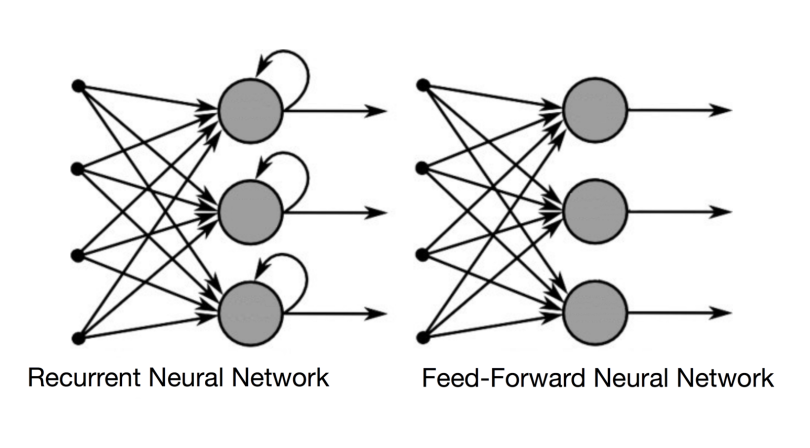
通常的 RNN 具有短期記憶。結合 LSTM,它們還具有長期記憶(稍後會詳細介紹)。
說明循環神經網絡記憶概念的另一個好方法是用一個例子來解釋它:
想像一下,你有一個普通的前饋神經網絡,並給它“神經元”這個詞作為輸入,它會逐個字符地處理這個詞。當它到達字符“r”時,它已經忘記了“n”、“e”和“u”,這使得這種類型的神經網絡幾乎不可能預測接下來會出現哪個字符。
然而,循環神經網絡能夠記住這些字符是因為它的內部記憶。它產生輸出,複製該輸出並將其循環回網絡。
簡單地說:循環神經網絡將過去添加到現在。
因此,RNN 有兩個輸入:現在和最近的過去。這很重要,因為數據序列包含有關接下來會發生什麼的關鍵訊息,這就是為什麼 RNN 可以做其他算法不能做的事情的原因。
與所有其他深度學習算法一樣,前饋神經網絡為其輸入分配一個權重矩陣,然後產生輸出。請注意,RNN 將權重應用於當前輸入以及先前的輸入。此外,循環神經網絡還將調整 梯度下降和隨時間反向傳播 (BPTT) 的權重。
另請注意,雖然前饋神經網絡將一個輸入映射到一個輸出,但 RNN 可以映射一對多、多對多(翻譯)和多對一(分類語音)。
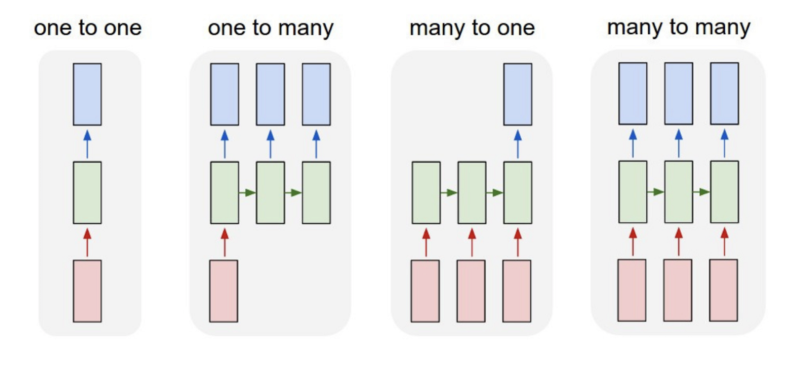
時間反向傳播
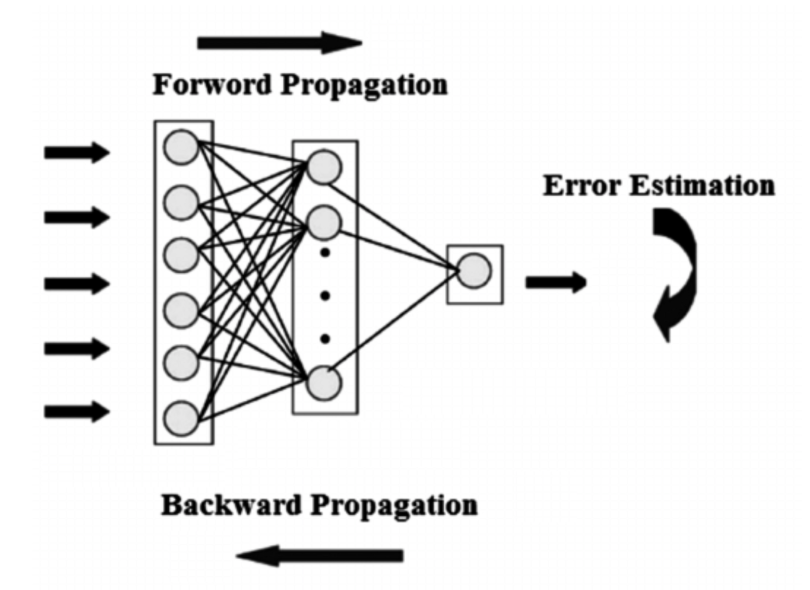
要了解反向傳播的概念,您首先需要了解正向和反向傳播的概念。我們可以用整篇文章討論這些概念,因此我將嘗試提供盡可能簡單的定義。
在神經網絡中,您基本上進行前向傳播以獲取模型的輸出並檢查此輸出是正確還是不正確,以獲取錯誤。反向傳播只不過是通過您的神經網絡反向查找誤差相對於權重的偏導數,這使您能夠從權重中減去該值。
然後通過梯度下降使用這些導數,梯度下降是一種可以迭代最小化給定函數的算法。然後它向上或向下調整權重,具體取決於哪個會減少誤差。這正是神經網絡在訓練過程中的學習方式。
因此,通過反向傳播,您基本上會在訓練時嘗試調整模型的權重。
下圖說明了前饋神經網絡中前向傳播和反向傳播的概念:
BPTT 基本上只是一個花哨的流行語,用於在展開的 RNN 上進行反向傳播。Unrolling 是一種可視化和概念性工具,可幫助您了解網絡中正在發生的事情。大多數情況下,在通用編程框架中實現循環神經網絡時,會自動處理反向傳播,但您需要了解它是如何工作的,以解決開發過程中可能出現的問題。
您可以將 RNN 視為一系列神經網絡,您可以通過反向傳播一個接一個地對其進行訓練。
下圖展示了一個展開的 RNN。在左側,RNN 在等號之後展開。請注意,等號之後沒有循環,因為不同的時間步被可視化並且訊息從一個時間步傳遞到下一個時間步。該圖還說明了為什麼可以將 RNN 視為一系列神經網絡。
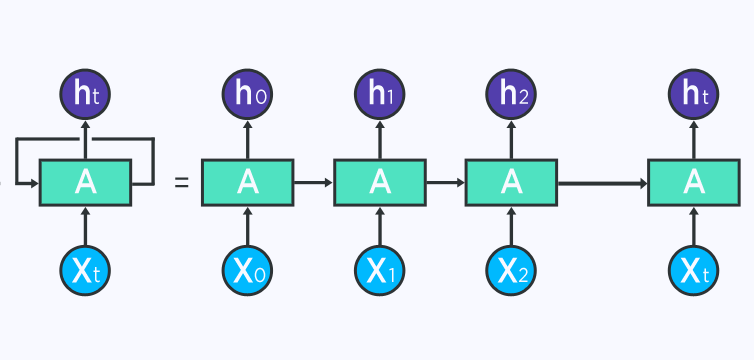
如果您使用 BPTT,則需要展開的概念化,因為給定時間步的誤差取決於前一個時間步。
在 BPTT 中,錯誤從最後一個時間步反向傳播到第一個時間步,同時展開所有時間步。這允許計算每個時間步的誤差,從而允許更新權重。請注意,當您有大量時間步長時,BPTT 的計算量可能會很大。
標準RNN的兩個問題
RNN 必須處理兩個主要障礙,但要理解它們,您首先需要知道什麼是梯度。
梯度是關於其輸入的偏導數。如果你不知道這意味著什麼,可以這樣想:梯度測量如果你稍微改變輸入,函數的輸出會發生多大的變化。
您也可以將梯度視為函數的斜率。梯度越高,斜率越陡,模型可以學習的速度越快。但是如果斜率為零,模型就會停止學習。梯度只是衡量所有權重相對於誤差變化的變化。
爆炸梯度
梯度爆炸是指算法在沒有太多理由的情況下對權重賦予了愚蠢的高重要性。幸運的是,這個問題可以通過截斷或壓縮梯度輕鬆解決。
消失的漸變
當梯度的值太小並且模型停止學習或因此花費的時間太長時,就會發生梯度消失。這是 1990 年代的一個主要問題,比爆炸梯度更難解決。幸運的是,Sepp Hochreiter 和 Juergen Schmidhuber 通過 LSTM 的概念解決了這個問題。
長短期記憶 (LSTM)
長短期記憶網絡 (LSTM) 是循環神經網絡的擴展,它基本上擴展了記憶。因此,它非常適合從間隔很長的重要經驗中學習。
LSTM 的單元用作 RNN 層的構建單元,通常稱為 LSTM 網絡。
LSTM 使 RNN 能夠長時間記住輸入。這是因為 LSTM 將訊息包含在內存中,就像計算機的內存一樣。LSTM 可以從其內存中讀取、寫入和刪除訊息。
這種記憶可以看作是一個門控單元,門控意味著單元根據它分配給訊息的重要性來決定是否存儲或刪除訊息(即,是否打開門)。重要性的分配是通過權重發生的,這也是算法學習的。這僅僅意味著它會隨著時間的推移了解哪些訊息是重要的,哪些訊息不重要。
在 LSTM 中,您有三個門:輸入門、遺忘門和輸出門。這些門決定是否讓新輸入進入(輸入門),刪除不重要的訊息(忘記門),還是讓它在當前時間步影響輸出(輸出門)。下面是具有三個門的 RNN 的圖示:
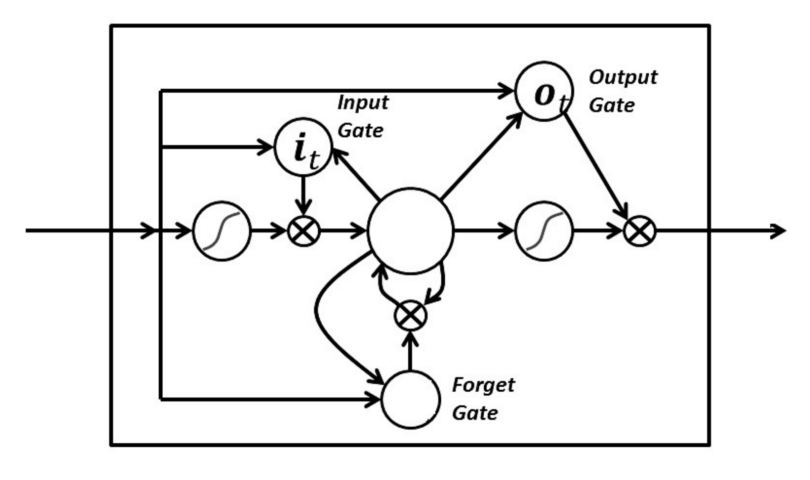
LSTM 中的門以 sigmoid 的形式模擬,這意味著它們的範圍從零到一。它們是模擬的這一事實使它們能夠進行反向傳播。
通過 LSTM 解決了梯度消失的問題,因為它使梯度保持足夠陡峭,從而使訓練相對較短且準確度較高。
概括
現在您對循環神經網絡的工作原理有了適當的了解,您可以確定它是否是用於給定機器學習問題的正確算法。
客戶只點Google第一頁自然搜尋結果
根據調查,出現在Google搜尋結果第一頁的網站會有高達88%的使用者會點擊,只有15%的使用者會去看第二頁的內容,故在搜尋引擎結果第一頁排序的網站就成為了絕佳的黃金店面,要想佔據有限位置讓品牌走進消費者心中就需要借助專業SEO公司的幫助。
關鍵字廣告只占整體點擊率的6%
試問自己,上一次點關鍵字廣告是幾年前的事? 這是人性,大家都想點擊最夯最有人氣的網站,而不是假假的廣告,因此,直接避開廣告跳到自然搜尋結果已成為每個人搜尋上的習慣。這也是許多公司為什麼願意花費比關鍵字廣告更多幾倍的費用來優化官網。




相關搜尋
- Sendspace 免費雲端存儲空間網路硬碟
- 進階加密標準 AESAdvanced Encryption Standard 簡介
- CSS margin padding 間距與邊界有什麼區別?
- 遞歸神經網路 RNN-Recurrent neural network 簡介
- ASP.NET Core middleware 中介軟體簡介
- 如何在 Windows 和 Visual Studio 中使用 ngrok 來測試 webhook
- Python opencv-Open Source Computer Vision Library簡述
- Python PIL 影像處理工具
- FreeNAS 企業儲存系統
- .NET 核心net core概述
- 什麼是 NGINX?建構網站的另一選項
- 構建linebot機器人的第一步
- Git diff 命令 - 如何比較程式碼版本中的更動
- pyenv 教學-Python 控管版本的好幫手
- Design pattern 軟體工程必須面對的設計模式
- 什麼是vim 文字編輯器?
- Django 教學-運用Django 開發網路程式
- 什麼是統一塑模語言 UML?
- Xcode 教學:什麼是 Xcode 以及如何開發IOS App
- 什麼是 DQN 強化學習模型
- 什麼是 DOM?
- 什麼是 Ansible?
- 主機的入侵檢測系統 (HIDS)簡介
- 什麼是 MQTT 及其工作原理
- Knn-machine learning 基礎最近鄰演算法
- 什麼是ROS?
- 什麼是 React Native?值得花時間學嗎?
- 運用MAMP簡單步驟建立local server
- Python tuple 元組基本語法概述
- Dijkstra algorithm:戴克斯特拉最短路徑算法
- 簡單SQL Server 教學
- 如何修復dns伺服器沒有回應
- 什麼是 Webhook?
- 學習Postman
- 運用Python plot - Python novice gapminder
- 了解ORM-object relational mapping:優點、缺點和類型
- LibreNMS – 一個全功能的 Linux 網路監控工具
- 運用ngrok輕鬆共享您的本地伺服器
- Google Meet 時間限制又回來了-了解一下這次您可以免費通話多長時間
- 如何 Ping port 遠端電腦特定port是否有開放
- Android Studio 簡介
- 理解SQL injection攻擊模式
- GDB the GNU Project debugger 介紹
- 什麼是 Spring Boot?
- 什麼是 CI CD?
- DuckDuckGo:Google的強勁對手不追蹤您的隱私
- Docker 初學者教學:基礎、架構、容器
- 簡單了解 ACL 訪問控制列表
- 最新Python教學
- 充分利用 Spotify 方案
- 學習 PHP 的 27 套最佳教材
- 什麼是k8s Kubernetes?
- 簡單了解Docker run運行指令
- 什麼是Jupyter?
- 什麼是 CTF Catch The Flag 如何開始安全攻防大戰!
- 使用 Windows cmd 命令提示字元的 6 種巧妙方法
- 最佳免費 PDF 編輯器
- iSCSI 網際網路小系統介面簡介
- Python 爬蟲開發環境簡介
- 如何修復電腦開機沒畫面?
- 什麼是資安? 資訊安全講給你聽
- 如何為你的電腦螢幕錄影?
- 什麼是Swagger?為什麼你的project需要它?
- 網速單位Mbps定義方式如何計算你的需求?
- 簡單了解 TypeScript
- 如何免費創建自己的郵件伺服器Mail server? 以HMail server為例
- 什麼是 DevOps?
- 如何使用 JMeter 進行網站性能和負載測試
- Google Flutter 簡介
- WordPress缺點 不適合使用WP的情況有哪些
- 了解網頁伺服器運作原理
- 動態網頁如何運作
- 如何使用微軟的遠端桌面連線
- 簡介電源管理IC-power ic
- 簡單理解以太網供電 PoE switch 交換機
- 什麼是Influencer?– 定義社交媒體影響者 [2022 年更新]
- 企業數位轉型成功方式有哪些?
- 什麼是 KOL 行銷以及它如何使您受益?
- 什麼是社群行銷?
- Instagram 廣告行銷完整學習
- WIX 是什麼如何幫助網路行銷
- 中小企業的 7 種主要行銷技巧
- 如何為您的企業制定清晰可執行的行銷策略
- Bing SEO:如何在Bing搜尋引擎上確保第一頁位置
- 初學者終極 WordPress SEO 教學
- YouTube SEO:如何為 YouTube 搜尋優化影片排名
- 什麼是AWD自適應設計?5 個啟發靈感的自適應網頁設計示例
- 網際網路 - WWW
- 人類還是機器人? 為您的 SEO 內容選擇最佳讀者
- 如何計算SEO的投資回報率ROI
- 什麼是 OneDrive?
- 如何在任何設備上下載 YouTube 影片
- 如何使用 LinkedIn 行銷您的業務
- Google Colab是什麼? 使用 Google Colab 的 4 個理由
- 簡單了解 SMTP Email傳輸協議
- Notion APP 初學者簡介
- 什麼是推特 Twitter,這熱門社交軟體是如何得到人們的喜愛?
- 什麼是 iCloud,如何使用它以增加生活的便利性?
- POP3-Post Office Protocol V3-郵局協議3在Email傳輸過程中所扮演的腳色
- 簡單了解 Google 雲端運算服務 (GCP)
- 如何應用免費線上 Trello 終極專案管理工具
- 疫情新生態-在家工作 WFH意思是什麼? - work from home
- 了解IMAP網際網路資訊存取協定
- 認識乙太網路供電 Power over Lan Power over Ethernet, PoE
- Anydesk-免費遠端桌面登入軟體簡介
- Google 雲端硬碟 Google drive 簡介
- 什麼是Discord?熱門通訊軟體介紹
- 何謂用戶代理 user agent?
- 什麼是 CGI-Computer-generated imagery電腦生成圖像?– 你需要知道的一切
- 11 個最佳圖片搜尋引擎介紹給您
- 什麼是應用伺服器-app server?
- Docker 簡介 - 比虛擬機器更輕量化的軟體運作環境
- 什麼是 IP 地址 – 定義和解釋
- 什麼是 VPN-Virtual Private Network?
- 什麼是 FTP - File Transfer Protocol 伺服器?
- 簡單認識canonical
- 簡單了解 Perl 語言
- 什麼是客製化網站設計?
- 什麼是 database 資料庫?定義,含義,類型與範例
- html alt text:是什麼,如何編寫,以及為什麼對 SEO 很重要
- Html 元描述 meta description 是什麼
- 什麼是 IPv6,為什麼採用過程需要這麼長時間?
- 什麼是 IPv4?IPv4路由當今的大部分網際網路流量
- 選擇網頁設計公司需要考慮的 5 件事
- DNS伺服器是什麼?如何設定?
- 運用網路快速賺錢的40種簡單方法
- 頁面文章中的錨文案或錨點文字Anchor Text對SEO優化的影響
- 什麼是Google更新?Google演算法的由來
- Google Hummingbird-什麼是Google蜂鳥演算法如何影響排名
- 什麼是轉化率 conversion rate optimization - CRO?如何計算和提高您的轉化率
- GOOGLE PENGUIN 了解Google企鵝演算法及更新運作方式
- 什麼是 HTML meta tag - 元標記
- 什麼是 robots.txt 文件?
- 9個網頁製作步驟建構新網站
- 如何規劃電子商務購物型網站
- 什麼是域名?什麼是網址URL?
- TWNIC是什麼(財團法人台灣網路資訊中心)?
- .htaccess 文件是什麼?
- 什麼是 FTP-為初學者解釋 FTP
- 簡單了解點擊率 CTR - Click Through Rate
- YouTube去廣告及廣告阻擋方法
- 如何使用Google商家檔案(Google我的商家)獲得更多客戶
- 最新Google AnalyticsGoogle分析終極教學
- 手機客群是您新的焦點小組
- 將連結建構付諸實踐
- 熟悉連結建構指標
- 如何規劃連結建立策略
- 最新Google Search Console使用教學
- 設定連結外拓計畫
- 尋找連結目標
- SEO就是連結建立競賽
- SEO中的連結類型簡介
- SEO初學者連結建立步驟
- 在地 SEO 關鍵字列表
- COVID-19 時期的在地 SEO優化策略
- Local SEO 的分析、自動化和報告
- 如何運用SEO技能制定強大的在地銷售策略
- 建立你的網站在地權威性
- 運用SEO專業知識來分析網站內容和製定發布策略
- 制定聲譽和評論策略
- On Page local SEO - 頁面搜尋引擎優化和在地商家列表
- Local SEO - 評估在地需求和分析在地市場型態
- 了解 Google 在地 SERP
- 在地搜尋引擎優化SEO策略步驟
- 優化過程中哪些關鍵字詞可以優先處理?
- 從關鍵字詞分析中創建關鍵字清單
- 關鍵字分析從種子關鍵字seed keywords開始
- 優化初期深入研究關鍵字對整體SEO運行過程的重要性
- 報告套板和免費資源
- SEO整體調整報表
- 建立SEO技術調整報告
- 如何撰寫SEO連結建立報告
- 內容、關鍵字和排名報告
- 通過SEO報告與客戶建立關係
- 給客戶的SEO 報告必備內容
- 如何實際操作SEO競爭對手分析
- 如何實際操作Google SEO 排名
- SEO術語和含義
- SEO 專家的操作策略 衡量和追踪過程直到成功
- 建立網站連結增加網站整體權威性
- 技術搜尋引擎優化
- On Page SEO 頁面搜尋引擎優化
- SEO關鍵字詞研究
- 買外部連結或買反向連結的風險
- 網頁設計中的麵包屑-範例與實際操作
- MVC架構簡介
- AMP是什麼?簡單了解加速移動頁面運作原理
- 搜尋引擎的工作原理
- 了解如何關鍵字排名優化您的網站
- 什麼是CMS內容管理系統?
- 網頁設計詳細步驟拆解
- 什麼是Proxy代理伺服器?它是如何運作的?
- 什麼是虛擬主機?虛擬主機是如何運作的?
- RWD響應式網頁設計 - RWD是什麼以及如何使用
- 了解HTML 設計網頁的第一步
- Server 伺服器是什麼?為我們的生活帶來哪一些便利性?
- Wordpress 由來以及架站須知
- 快速了解網站設計基本概念
- 什麼是 ssl 憑證、TLS 和 HTTPS?
- 何謂網站連結-URL是什麼,了解URL意思
- SEO優化
- SEO公司
- SEO顧問